FireGPG is a Firefox extension which brings an interface to GPG functions. It's capable of signing, verifying, encrypting and decrypting text on the fly using GnuGPG.
It also integrates with Gmail, making it possible to run GPG functions on mail messages. One of its features is auto-verification of mail messages, which are detected as PGP-signed.
After a mail message has been verified, it is printed below the message whether the signature matches the message and if it does, issuer name is printed as well.

However (in version 0.46), the issuer name is not sanitized or validated against malicious input, so it makes FireGPG vulnerable to Cross Site Scripting. If the issuer name (which is provided with the public key) contains a malicious JavaScript, it will be executed under Gmail's context!. An XSS under Gmail allows the attacker to impersonate to the victim by controlling his mailbox, steal his cookies and so on.
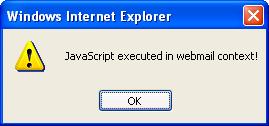
To exploit this vulnerability, the attacker sends the victim a message signed with his malicious PGP key, and then convinces him to import the attacker's public key block (which contains the malicious issuer name). The key can be imported manually, or by using a public key repository. It is reasonable that the victim will not notice the malicious issuer name since public keys are usually distributed as base64 blocks, or identified by their Key ID when retrieved from a public key server. Once the victim views the signed message in his mailbox, FireGPG will automatically verify it and inject the malicious payload into Gmail's DOM, which is immediately executed. The screenshot below illustrates an injection of a javascript into Gmail's DOM by setting the issuer name to "<script>alert(document.domain)</script>"

This type of XSS is interesting because a browser bug leads to an XSS. it is both similar and dissimilar to DOM-based XSS. It resembles to DOM-based XSS because the attack cannot be detected by the affected domain. But unlike DOM-based XSS, flaws of this variant are not originated from the developers of the affected domain.
Looking at FireGPG's case, Gmail is not responsible for the flaw, yet the XSS occurs under its DOM. Looking at Yair Amit's last post, the website which an HTML file is downloaded from is not responsible for the XSS, Internet Explorer is.
It should be noted that FireGPG's team has been very responsive and it took them about 21 hours since our disclosure to provide a remedy to the flaw. This shows they are security aware and are committed to the protection of their end-users. It is an excellent example of how to handle security related bugs correctly. Many vendors do not distinct security bugs from other bugs, IMHO this is a bad approach - security related bugs should be fixed as soon as possible, and not in the next service pack.